Torna all’indice generale >versione in C++
Fasi di una applicazione
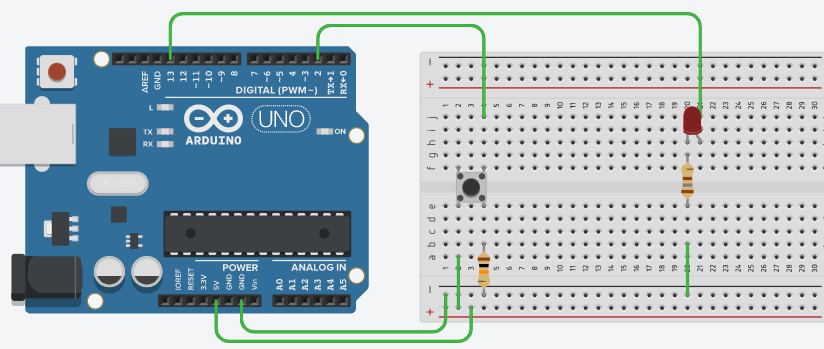
Un microcontrollore possiede la specificità di avere integrate nello stesso chip un gran numero di periferiche con le quali una generica applicazione in qualche modo deve colloquiare.
il colloquio si può realizzare sostanzialmente usando due tecniche di gestione:
- polling. Le periferiche vengono interrogate periodicamente osservando i loro stato, se questo è ready cioè pronto per una determinata modalità di accesso (lettura, scrittura o lettura/scrittura) allora l’applicazione legge il valore della periferica con una opportuna istruzione di I/O. Questa tecnica si dice sincrona poichè i tempi di accesso alla periferica sono prevedibili in quanto stabiliti dall’applicazione).
- interrupt. Le periferiche segnalano la loro disponibilità (o necessità) di comunicare con la CPU (e quindi con l’applicazione) solamente quando sono pronte inviando un particolare segnale che viaggia dalla periferica alla CPU attraverso il bus controlli, detto interrupt. Il segnale di Interrupt sospende temporaneamente l’esecuzione dell’applicazione e attiva una funzione di servizio, detta ISR (Interrupt Service Routine), che gestirà la comunicazione con la periferica. Questa tecnica si dice asincrona poichè i tempi di accesso alla periferica non sono prevedibili in quanto stabiliti da un sistema esterno fuori dal controllo del nostro sistema.
Il polling degli ingressi è una attività che, insieme al codice del programma, si effettua all’interno del loop().
Una ISR() è una funzione a parte, esterna al loop() che viene richiamata in risposta ad un evento di interrupt.
Sia che venga notificato con un interrupt, sia che venga rilevato dall’appplicazione, in qualche modo si genera un evento di input che deve essere gestito.
Eventi di input possono essere di varia natura: l’input di un pulsante, l’input da una seriale, l’input da una porta digitale in genere. Qualunque sia il tipo di dispositivo, nello sviluppo del ragionamento che faremo adesso, lo possiamo assimilare ad un generico sensore.
In definitiva, se il nostro “sensore” è un pulsante, dovremmo vedere la pressione del pulsante come un generico evento di input al quale il microcontrollore risponde generando un output dopo avere elaborato una logica di comando. Possiamo interpretare la logica di comando come l’algoritmo che genera la risposta all’evento.
Il discorso è del tutto generale e non vale solo per i pulsanti ma per qualunque ingresso e per qualunque applicazione eseguita da un microcontrollore, che, non a caso, in ambito industriale è spesso indicato come Logic Solver.
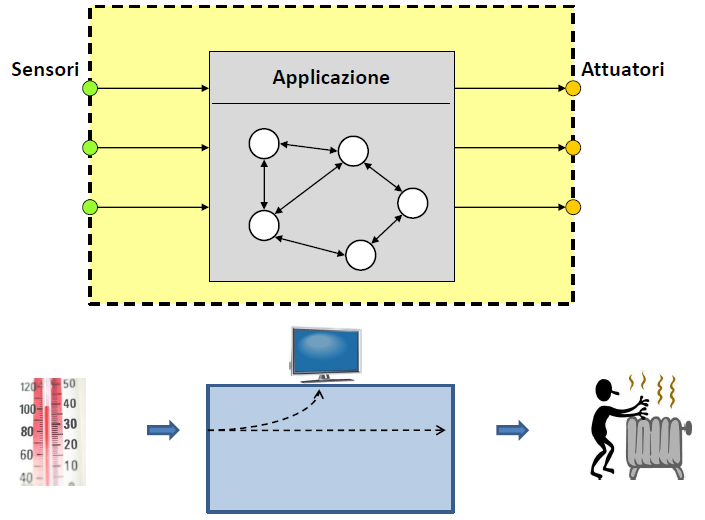
Quindi le fasi di una generica applicazione dovrebbero essere nell’ordine:
-
Lettura ingressi
-
Elaborazione logica di comando
-
Scrittura uscite
Ad es.:
val = digitalRead(pulsante) # lettura ingressi
stato = not(stato) # calcolo logica di comando
digitalWrite(led,stato) # scrittura uscite
In un microcontrollore le tre fasi sono eseguite in quell’ordine ma, se inserite dentro la funzione loop(), sono eseguite periodicamente, all’infinito, fino allo spegnimento della macchina.
Questo fatto impone alcune riflessioni:
-
Quanto spesso vengono eseguite queste fasi? Posso controllare la loro periodicità?
-
Devono essere eseguite sempre? Posso filtrare la loro esecuzione?
-
Sono con memoria? Cioè posso legare il risultato di una fase a quello delle fasi eseguite in precedenza?
Quanto spesso (azioni periodiche).
-
Se le metto “direttamente” dentro il blocco loop() vengono eseguite molto spesso, anzi più spesso che si può. La periodicità, cioè il numero di volte al secondo, dipende dalla velocità della CPU e dalla velocità delle singole operazioni e non è possibile stabilirla con precisione.
-
Se le metto nel loop() ma dentro un blocco di codice condizionale la cui esecuzione avviene periodicamente in certi istanti prestabiliti (ad esempio ogni 10 secondi) allora possono essere eseguite meno frequentemente. Ho realizzato così un filtraggio degli eventi periodici da eseguire nel futuro. La periodicità dell’esecuzione è controllabile con precisione mediante algoritmi di scheduling (pianificazione nel tempo) che possono essere realizzati in vario modo. In genere, a basso livello, i modi periodici (o sincroni) sono tre:
-
Ritardo dell’esecuzione mediante funzione delay() impostabile ad un tempo di millisecondi prefissato.
-
Polling della funzione millis() nel loop che permette di scegliere l’istante di tempo adatto per eseguire un certo blocco di codice posto all’interno del loop (tipicamente dentro un blocco if-then-else con una condizione che valuta millis())
-
Interrupt generato da un timer HW che permette di eseguire una ISR(), definita al di fuori dal loop(), allo scadere del timer.
-
Azioni eseguite non sempre (azioni aperiodiche).
Le azioni da eseguire in base al verificarsi di certe condizioni non periodiche. Se il loro accadere non è il frutto di nessun algoritmo in esecuzione nel sistema perchè sostanzialmente dipende da fattori esterni al sistema e quindi non prevedibili, quali valori degli ingressi o segnali di interrupt, allora si possono definire come eventi asincroni.
Gli eventi aperiodici possono essere gestiti:
- fuori dal loop() grazie alla chiamata di una corrispondente callback attivata da un segnale di interrupt.
- dentro il loop() tramite il polling di una condizione di test dell’evento valutata all’interno di una istruzione di selezione. L’istruzione di selezione prende delle *decisioni mutuamente esclusive in merito all’evento stesso eseguendo il blocco then o quello else di un costrutto if-then-else. La condizione di selezione potrebbe valutare:
- il tempo. Lo faccio durare un certo tempo, o lo faccio accadere in un certo tempo, realizzando così nel loop() un filtraggio degli eventi aperiodici da eseguire nel futuro.
- altri input. Confronto il valore attuale di un ingresso con quello di altri ingressi.
- lo stato del sistema. Se il motore è in movimento faccio una certa cosa se no non la faccio.
Di seguito la fase di scrittura delle uscite non viene eseguita ad ogni loop ma solo se un certo ingresso ha un determinato valore:
if in == HIGH:
digitalWrite(led,closed) #scrittura uscita
Azioni con memoria (persistenza di una variabile).
Le variabili in un microcontrollore possono essere dichiarate:
- all’interno del loop() e allora si dicono locali alla funzione loop(). Le variabili locali hanno:
- il loro ciclo di vita, cioè l’intervallo temporale tra la loro allocazione e la loro deallocazione in RAM, tutto all’interno di un singolo ciclo di loop(). Esse nascono (vengono dichiarate e quindi allocate), evolvono (vengono lette e modificate) e muoiono (vengono deallocate) all’interno della funzione loop(). Questo è il motivo per cui le variabili locali al loop(), non godendo della proprietà di persistenza tra un loop e l’altro, diventano immancabilmente, ad ogni nuovo ciclo, nuovi dati che occupano le stesse posizioni in memoria che avevano i vecchi al ciclo precedente.
- Il loop() è anche l’ambito di visibilità (scope) delle variabili locali, cioè dichiarate al suo interno, perchè solo all’interno del loop possono essere accessibili in lettura o in scrittura. Al di fuori del loop() variabili con lo stesso nome sono ancora ammesse ma sono sempre considerate variabili diverse.
- all’esterno del loop() e allora si dicono esterne alla funzione loop(), se poi queste sono dichiarate pure esterne ad ogni funzione del progetto (loop compreso) allora si dicono globali.
- Le variabili globali hanno il loro ciclo di vita che dura per tutta l’esecuzione del programma: sono dichiarate al di fuori del loop(), inizializzate nel setup() e lette e modificate all’interno del loop().
- Le variabili globali hanno la loro visibilità in tutte le funzioni del progetto, cioè sono accessibili, in lettura e in scrittura, sia da parte del codice inserito nel loop() che da quello che sta altrove, inserito all’interno di qualunque altra funzione definita nel progetto.
La persistenza di una variabile globale nel loop() potrebbe servire a:
- Tenere memoria degli ingressi al loop precedente fino al loop successivo. Cioè conservare il valore corrente di uno o più ingressi in una variabile per poi poterlo “consumare” cioè leggere ed utilizzarlo durante l’esecuzione del loop successivo.
pval = val # ultima istruzione che chiude loop() - Tenere memoria dello stato del mio algoritmo, cioè traccia di quelle informazioni fondamentali che ne determinano il comportamento nel tempo (dedotte dalla storia di ingressi e da quella di altre variabili di stato) mediante la loro conservazione all’interno di una o più variabili di stato che vengono lette ed aggiornate ad ogni loop. Una variabile di stato divide l’evoluzione futura del sistema in un insieme di epoche in cui stessi ingressi del sistema potrebbero potenzialmente generare uscite differenti a seconda dello stato del sistema. Lo stato del sistema, in questo senso, è assimilabile ad una sorta di “umore” (mood) del sistema che lo porta a reagire in maniera differente alle stesse sollecitazioni a seconda del particolare valore che esso assume in un certo momento.
Ad esempio se deduco il nuovo stato da quello precedente:
stato = not stato
oppure, se deduco il nuovo stato da un ingresso e dallo stato precedente:
if in == HIGH and stato == 0:
stato = 1
In entrambi i casi precedenti le informazioni devono “sopravvivere” tra un loop e l’altro, cioè il loro valore non deve essere cancellato al termine dell’esecuzione della funzione loop() e ciò può essere ottenuto dichiarando le variabili di memoria globali, cioè dichiarandole all’esterno di tutte le funzioni del sistema, compresa la funzione loop().