SCHEDULAZIONE CON I THREAD
Base teorica
I thread, detti anche processi leggeri, sono dei flussi di esecuzione separati da quello principale (il programma main) che procedono indipendentemente l’uno dall’altro e soprattutto in maniera parallela cioè contemporaneamente l’uno con l’altro. Il parallelismo può essere:
- reale se flussi di esecuzione diversi sono eseguiti da core (o CPU) diversi. Possiede la proprietà di effettiva simultaneità nell’esecuzione di più istruzioni.
- emulato se flussi di esecuzione diversi sono eseguiti dallo stesso core della stessa CPU. La proprietà di simultaneità è relativa all’esecuzione di più programmi nello stesso momento ma con istruzioni dell’uno e dell’altro eseguite in momenti diversi (tecnica dell’interleaving).
Normalmente una istruzione delay(x) fa attendere per x secondi non solo l’esecuzione di un certo task ma anche quella di tutti gli altri che quindi, in quel frattempo, sono bloccati. Il motivo risiede nel fatto che tutti i task condividono il medesimo flusso di esecuzione (o thread) e, se questo viene fermato, viene fermato per tutti i task.
Se però due o più task vengono eseguiti su thread differenti è possibile bloccarne soltanto uno con un delay impedendo temporaneamente ad uno dei suoi task di andare avanti, ma lasciando liberi tutti gli altri task sugli altri thread di proseguire la loro esecuzione. Questo perchè thread differenti sono assimilabili a flussi di esecuzione differenti eseguiti su CPU (logiche) differenti. In realtà le diverse CPU logiche sono solamente virtuali perchè condividono un’unica CPU fisica.
Avere più flussi di esecuzione paralleli fornisce quindi il vantaggio di poter realizzare gli algoritmi in maniera lineare suddividendoli in fasi successive la cui tempistica può essere stabilita in maniera semplice ed intuitiva impostando dei ritardi, cioè dei delay, tra una fase e l’altra. La separazione dei flussi permette una progettazione indipendente degli algoritmi eccetto che per i dati comuni a più flussi (thread), per i quali deve essere sincronizzato l’accesso con opportuni meccanismi.
Anche i processi sono flussi di esecuzione indipendenti che procedono in parallelo su una o più CPU, esiste però una differenza pratica notevole con i thread:
- nei processi sia input/output, che area dati globale che area dati locale (stack) sono indipendenti e separate in zone diverse della memoria RAM.
- nei thread input/output e area dati globale sono in comune nella stessa posizione in RAM mentre soltanto le aree dati locali (stack) sono indipendenti e separate in zone diverse della memoria RAM.
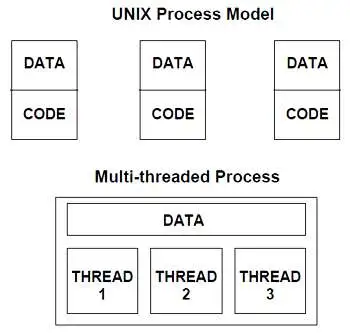
Ma come è possibile che thread diversi possano essere mandati in esecuzione contemporaneamente su un’unica CPU fisica?
In realtà ad essere eseguiti contemporaneamente sono soltanto i task, cioè i programmi ed i relativi algoritmi, le istruzioni in linguaggio macchina che li compongono vengono invece eseguite a turno, un blocco di istruzioni alla volta. La durata del turno viene detta quanto di tempo. Terminato il quanto di tempo di un thread si passa ad eseguire le istruzioni di un altro thread nel quanto di tempo successivo. Ciò accade a patto che i thread siano “preemptive” cioè supportino il prerilascio della risorsa CPU prima del termine naturale del task (il comando return o il completamento del task). Le istruzioni accorpate in un quanto potrebbero non coincidere esattamente con un multiplo intero delle istruzioni ad alto livello, ci potrebbe essere, ad esempio, metà di un’assegnazione in un quanto e e l’altra metà in un’altro. Le istruzioni atomiche, cioè indivisibili, sono soltanto quelle in linguaggio macchina.
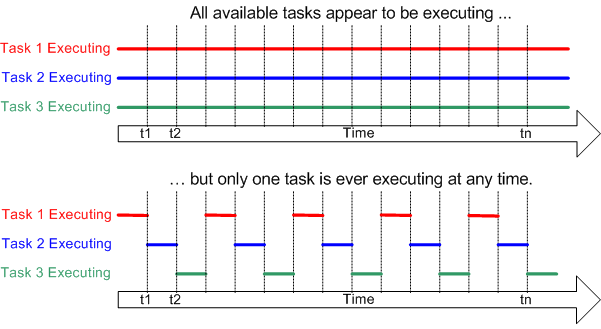
Normalmente i thread possono lavorare in due modalità operative:
- prempitive o competitiva. Se un task di un thread possiede una risorsa (ad esempio la CPU) ed è bloccato in attesa di un input o di un un delay(), viene marcato come interrompibile in maniera trasparente al task, senza che questo se ne accorga. Allo scadere di un timer HW, il task viene interrotto da un segnale di interrupt che blocca il flusso di esecuzione corrente e assegna la risorsa CPU ad un altro thread tra quelli che, in quel momento, aspettano di andare in esecuzione (stato ready).
- “cooperative” cioè cooperativa. Se un task di un thread possiede una risorsa (ad esempio la CPU) ed è bloccato in attesa di un input o di un una qualsiasi altra risorsa, esso stesso decide spontaneamente di cedere il controllo della CPU allo schedulatore invocando la sua esecuzione con un suo comando inserito nel codice del task (ad es. yeld()). Lo schedulatore assegna la risorsa CPU ad un altro thread tra quelli che, in quel momento, aspettano di andare in esecuzione (stato ready).
Di seguito è riportata una possibile rappresentazione della macchina a stati dei thread:
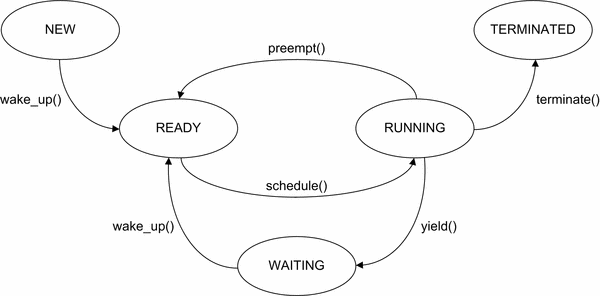
Ogni singolo stato in realtà può rappresentare una situazione comune a molti thread per cui è opportuno associare a ciascuno un elenco di thread organizzati in una coda. Se più thread posseggono i requisiti per uscire da un certo stato, la politica più semplice per farlo è la FIFO (First in First out), cioè tra i thread abilitati a uscire, estrae dalla coda quello che vi era entrato per primo.
La transizione da uno stato all’altro avviene in seguito ad un evento che può essere sia interno che esterno al thread. In genere, dallo stato running, si va in stato di attesa (WAIT) per:
- attesa di un evento di input esterno
- attesa dello scadere del tempo di uno sleep del thread (istruzione delay())
- istruzione yeld() eseguita nel codice del thread
- scadere del timer HW di sistema che assegna il tempo di CPU per quel thread
In figura sono indicate alcune funzioni tipiche:
- schedule() viene richiamata dallo schedulatore ogni volta che una CPU diventa disponibile per l’esecuzione di un thread. schedule() deve scorrere la coda dei thread nello stato ready, selezionare il prossimo thread da eseguire secondo un dato algoritmo di scheduling ed eseguire il cambio di contesto dal thread corrente al nuovo thread su quella CPU.
- preempt() a seguito dell’interruzione del thread corrente da parte del timer HW, questa funzione esegue il cambio di contesto dal thread corrente a quello dello schedulatore.
- wake_up() è una funzione che, richiamata allo scadere di un evento esterno al thread interrotto, lo “risveglia” mettendolo nella coda dei processi pronti (ready) per essere eseguiti. Può essere richiamata da un evento che avviene in un altro thread (ad es. una condizione su una variabile che si avvera) oppure può essere la fine dell’attesa dell’input che bloccava quel thread o, ancora, può essere collegata allo scadere del tempo di un ritardo delay(), che è la situazione che esploreremo nei prossimi esempi.
Vantaggi dei thread
Abbiamo visto che usare i delay per progettare i tempi di un task è più semplice perchè la programmazione rimane quella lineare a cui è solito ricorrere un programmatore per pensare gli algoritmi ma, in questo caso, è anche molto meno costosa in termini di efficienza che in un programma a singolo thread dato che la CPU può sempre servire tutti i task nello stesso momento (in maniera reale o simulata).
Può capitare, specie in dispositivi con risorse HW molto ristrette, che i thread non siano interrompibili ma possano lavorare solo in modo “cooperativo”, allora, in questo caso, alcune librerie forniscono una funzione delay() alternativa che contiene al suo interno il comando yeld() di rilascio “spontaneo” della CPU. In questo modo è preservata, anche su quei dispositivi, la possibilità di adottare uno stile di programmazione sequenziale degli algoritmi.
Un altro vantaggio per il programmatore è che la gestione della schedulazione è trasparente alla applicazione che deve essere schedulata, nel senso che l’algoritmo che deve gestire la schedulazione non deve essere incluso nel codice dell’applicazione. Qualcuno deve comunque gestire la schedulazione nel tempo dei thread e questo qualcuno è un modulo SW diverso dall’applicazione che può:
- essere fornito da una libreria apposita
- essere incluso in framework di terze parti (middleware)
- essere fornito dal sistema operativo presente sulla macchina
Il costo da pagare è una certa dose di inefficienza residua perchè la shedulazione dei thread può essere fatta in maniera più o meno sofisticata ma comunque richiede l’utilizzo di un certo ammontare della risorsa CPU. Il peso di queste inefficienze potrebbe diventare insostenibile in presenza di molti task che girano su sistemi con limitate risorse di calcolo, come sono tipicamente i sistemi embedded.
Riassumendo, la schedulazione mediante thread comporta:
- vantaggio. Maggiore semplicità nella progettazione dei programmi, grazie alla possibilità di utilizzare uno stile lineare di programmazione.
- vantaggio. Maggiore semplicità nella progettazione dei programmi che non devono realizzare la logica della schedulazione dei task ma solo quella interna al singolo task.
- svantaggio. Minore efficienza nell’uso della risorsa CPU che deve comunque eseguire un thread a parte di gestione delle schedulazioni sugli altri thread.
- svantaggio. Bisogna conoscere le API di libreria con cui viene realizzato il multithreading in un certo sistema con un certo linguaggio specifico. Le maniere possono essere parecchie per cui potrebbe essere utile ricorrere ad interfacce standard consolidate (ad esempio Thread POSIX)
- svantaggio. la schedulazione, cioè il passaggio da un thread all’altro, è comandata dallo schedulatore secondo una tempistica che, di base, non è governata dal programma principale, per effetto di ciò potrebbe diventare molto probematica la gestione delle risorse condivise tra un thread e l’altro. Cosa accade se due istruzioni di due task differenti scrivono contemporaneamente sullo stessa variabile globale? E se modificano contemporaneamente lo stesso registro di una periferica?
L’ultimo svantaggio è particolarmente critico e può comportare l’introduzione di errori difficilmente rilevabili, anche dopo innumerevoli prove sistematiche. La progettazione della gestione delle risorse condivise, e della gestione della comunicazione tra i thread in generale, deve essere molto accurata e ben ponderata. Vari strumenti SW e metodologie ad hoc permettono di affrontare più o meno efficacemente il problema.
Utilizzo in pratica
Ogni thread realizza un flusso di esecuzione parallelo a quello degli altri thread, inoltre ognuno possiede un proprio loop() principale di esecuzione in cui realizzare le operazioni che tipicamente riguardano le tre fasi di lettura degli ingressi, calcolo dello stato del sistema e della sua risposta e la fase finale di scrittura della risposta sulle uscite. Il loop principale può essere definito sotto forma di ciclo infinito come ad esempio:
# loop del thread (eseguito all'infinito)
while True:
# codice del thread
# .........................
oppure sotto la forma di loop condizionato dal valore di una variabile globale, ad es. isrun, che può interrompere il thread, facendolo terminare, una volta che questa viene negata nel loop() principale:
# loop del thread
while isrun:
# codice del thread (eseguito più volte)
# .........................
# istruzioni eseguite (una sola volta) alla chiusura del thread
Le fasi di lavoro del loop possono essere schedulate (pianificate nel tempo) dagli usuali delay() bloccanti che permettono la progettazione lineare di un algoritmo nel tempo. In realtà, una volta che il thread che ha in uso la CPU entra in un delay(), lo schedulatore, che adesso è di tipo preemptive, sottrae il controllo della CPU al thread corrente e lo assegna ad un altro thread che, in quel momento, è in attesa di esecuzione.
Modalità cooperativa
Per quanto riguarda la definizione di un task va ricordato che l’interno del loop del task ogni ramo di esecuzione potrebbe essere reso non bloccante inserendo, la funzione time.sleep(10) se il flusso di esecuzione deve essere bloccato temporaneamente per un certo tempo fissato, oppure la funzione time.sleep(0) se questo non deve essere bloccato. Ciò serve a richiamare lo schedulatore almeno una volta, qualunque direzione di esecuzione prenda il codice, in modo da cedere “spontaneamente” il controllo ad un altro task al termine del loop() del task corrente. La cessione del controllo dello schedulatore ad ogni ramo di esecuzione è facoltativa perchè comunque gli altri task verrebbero eseguiti (il sistema è preemptive).
Sia time.sleep(0) che time.sleep(10) cedono il controllo della CPU allo schedulatore che lo assegna agli altri task che eventualmente in quel momento hanno scaduto il tempo di attesa di un loro delay.
Esempio
Esempio di realizzazione di due task che eseguono un blink mediante delay() insieme ad altre generiche operazioni svolte nel main (piattaforma Espress if ESP32, IDE Arduino e librerie thread preemptive):
https://wokwi.com/projects/370506201490571265
#
# example ESP32 multitasking
# phil van allen
#
# thanks to https://youtu.be/iyoS9aSiDWg
#
import _thread as th
import time
from machine import Pin
blink1_running = True
blink2_running = True
led1 = Pin(4, Pin.OUT)
led2 = Pin(13, Pin.OUT)
def blink1(delay):
while blink1_running:
led1.value(not led1.value())
time.sleep(delay)
led1.value(0)
def blink2(delay):
while blink2_running:
led2.value(not led2.value())
time.sleep(delay)
led2.value(0)
print("Starting other tasks...")
th.start_new_thread(blink1, (0.5,))
th.start_new_thread(blink2, (0.25,))
count = 0
while True:
print("Doing stuff... " + str(count))
count += 1
if count >= 10:
break
time.sleep(1)
print("Ending threads...")
blink1_running = False
blink2_running = False
Blinks a tempo con una sola funzione
Esempio di realizzazione di due task che eseguono un blink mediante delay() insieme ad altre generiche operazioni svolte nel main (piattaforma Espress if ESP32, IDE Arduino e librerie thread preemptive). (Link simulatore online https://wokwi.com/projects/356375056713025537)
I blink sono due e si svolgono in maniera indipendente su due thread separati. La funzione di blink è unica con due parametri (potenzialmente anche di tipo diverso) passati alla funzione pthread_create() con un parametro array.
import _thread
import time
from machine import Pin
def blink(led, t):
while True:
led.value(not led.value())
time.sleep(t)
led1 = Pin(12,Pin.OUT)
led2 = Pin(18,Pin.OUT)
_thread.start_new_thread(blink, (led1,1))
_thread.start_new_thread(blink, (led2,2))